Engineering · research · releases
Blog
Release notes, methodology dives, and benchmarking deep-dives. New posts land alongside major releases and research findings.
2026·06·20
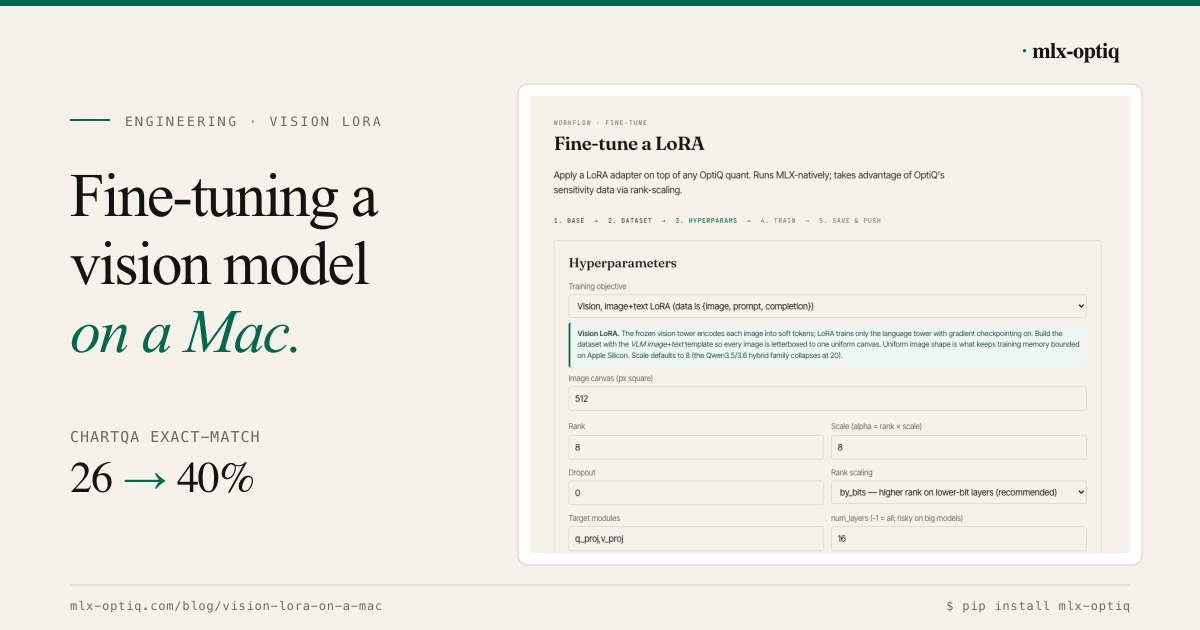
Fine-tuning a vision model on a Mac
OptiQ now fine-tunes the language tower of a quantized VLM on image+text data, locally on a 24 GB Mac. A LoRA on
Qwen3.5-0.8B-OptiQ-4bit lifts ChartQA exact-match from 26 to 40%. The two walls we hit (memory ratcheting on variable image sizes, and mode collapse on short targets) and the fixes (uniform letterbox + gradient checkpointing, gradient clipping + lower LR), plus a Lab dataset template and Fine-tune wizard for the whole flow.engineering

2026·06·19
A 122-billion-parameter model, on a laptop
mlx-optiq 0.2.5 runs Qwen3.5-122B-A10B on a 36 GB Mac by streaming its mixture-of-experts off SSD: 12 GB stays resident, the other 35 GB is read one expert at a time. The quant is a 2-bit
static allocation (44 GB on disk), the new no-measurement method that assigns bits by architecture and matches the calibration method on small models at 125× the convert speed. Proof it works: the model wrote and played its own Flappy Bird.release

2026·06·06
mlx-optiq can see: image + text on Gemma-4 and Qwen3.5/3.6
Image+text on the Gemma-4 and Qwen3.5/3.6 families. One bf16 vision sidecar makes the same published repo load text-only under stock
mlx-lm and full image+text under OptiQ, with no separate vision build and no mlx-vlm runtime dependency. Three vision architectures (SigLIP, the encoder-free Gemma-4 12B unified, and the Qwen3-VL tower) vendored and reproduced bit-exact (max|Δ|=0.0). Upload a picture in the Lab, or send an image_url to optiq serve: counting, shapes, colors, OCR, charts, and spatial questions all answer correctly.release

2026·06·01
A 1B humanizer that matches human writing on an AI detector
Stacked SFT + DPO LoRAs on
MiniCPM5-1B-OptiQ-4bit close 100% of the gap to human writing on the RADAR AI detector. P(AI) drops from 0.51 (source) to 0.37 — exactly matching the human reference. The recipe uses OptiQ 0.1.4's --mount-adapter for textbook DPO continuation and per-request adapter stacking at serve time. Two 120 MB adapters on a 875 MB base, all local on a 24 GB Mac.engineering

2026·05·22
Gemma-4 spec decoding on Apple Silicon
First MLX port of Google's Gemma-4
-assistant drafter. 1.18x decode geomean across five prompt categories on E4B with the 4-bit OptiQ quant, 31% acceptance, γ=1 greedy. Two RMSNorm-shaped formula bugs that took us from 0% to 33% acceptance, plus the bf16 multi-token verify artifact we cannot route around. Wired into OptiQ Lab Server as "Spec drafter".research

2026·05·21
Tools in OptiQ Lab chat: local web search, sandboxed Python, and a terminal
v0.1.0 ships three tools the model can call locally: DuckDuckGo search, Python in an AST-checked sandbox, and a bash terminal in the same sandbox with token-aware command blocking. Healer for six malformed tool-call shapes. 25-turn budget with duplicate-call de-dup and a budget-exhausted re-prompt. Stop button that SIGKILLs the running subprocess. Matplotlib output renders inline.
release

2026·05·21
When 4-bit KV cache uses more memory than fp16, and how OptiQ fixes it
Stock mlx-lm 4-bit KV cache on a 24 GB Mac at 32k context actually peaks higher than fp16 (16.35 GB vs 11.51 GB). OptiQ's streaming converter and FlashAttention-2 N-tiling drops u4 peak to 7.60 GB — 34% below fp16. At ±2% fp16 speed parity. Mixed-precision KV scores 33% better than uniform 4-bit at the hash-hop hops=3 differentiation point.
research

2026·05·19
Getting MTP to actually work on Apple Silicon
Wiring Multi-Token Prediction speculative decoding into OptiQ took three fixes: a duplicated model load, a wrong probabilistic verify, and untruncated sampling distributions. We landed at 1.20x / 1.32x / 1.40x on Qwen 4B / 9B / 27B with greedy decoding on a 24 GB M4 Mac, within 5 percent of unsloth's 1.4x on the same model class on an RTX 6000. Plus the math for why depth 2 does not help on Metal.
research

2026·04·28
The mlx-optiq eval framework: six benchmarks, one Capability Score
GSM8K-50 alone misses tool-calling and long-context regressions. The two-stage eval (KL + GSM8K-50 for triage, MMLU + GSM8K + IFEval + BFCL + HumanEval + HashHop for headlines) drives every quant we ship. Plus the auto-resolved KL reference, sandboxed code execution, and a single Capability Score that's the unweighted mean of all six.
methodology

2026·04·28
optiq.jsonl: a six-domain calibration mix for mixed-precision quantization
WikiText-2 measures prose; modern LLMs do prose, reasoning, code, agent loops, tool-calling, and constraint-following instructions. We replaced the calibration set with 40 hand-curated samples across all six domains, bundled inside the package, fully reproducible. What you calibrate on is what you protect.
engineering

2026·04·25
Gemma-4 lands on mlx-optiq: four sizes, +32 pp on the small one
Adding Google's full Gemma-4 instruct lineup: e2b, e4b, 26B-A4B sparse MoE, and 31B dense. The +32-point GSM8K recovery on gemma-4-e4b is the cleanest mixed-precision win we have. Plus the shared-KV caveat that means you'll want Qwen for quantized-KV serving.
engineering

2026·04·17
TurboQuant: postmortem on a research path we didn't ship
We built rotated-space KV attention with a custom Metal kernel. The benchmarks looked good: 100 % needle retrieval at 4-bit vs 73 % for affine. We still chose affine for the shipping path. Plain writeup of the technique, the numbers, and why the marginal win didn't justify a parallel serving stack.
postmortem

2026·04·08
Sensitivity-aware LoRA: fine-tuning that respects the bit budget
The same per-layer signal that drives mixed-precision quantization also drives adapter rank. 8-bit-quantized layers get 2× the adapter rank of 4-bit-quantized ones at the same parameter budget. Validation loss drops 12 % in head-to-head A/Bs. Plus the empirical training-ceiling map for a 36 GB Mac across all 10 supported models.
engineering

2026·03·20
Not All Layers Are Equal: mixed-precision quantization for weights and KV cache on Apple Silicon
The research foundation behind mlx-optiq. Some layers are 56× more sensitive than others. The KV cache becomes the dominant memory cost at long contexts. Mixed-precision recovers what uniform 4-bit drops; mixed-precision KV fixes the perplexity collapse uniform 4-bit causes.
research